Naive Web Data Engineering Tales: Building Robust Optical Character Recognition #1
I <3 Data Engineering, BUT .. #
Problem is I am not a data engineer. I am a hacker. I only make things so let me introduce you to my new series Naive Data Engineering!
Over the span of a few years, every once in a while a client or project will come across my hands with OCR (Optical Character Recognition) plastered all over it. Especially when the data that will need to be engineered and massaged are images or video. I remember some infamous drunken episodes of trying to get reliable Computer Vision web applications to work during my Masters’ work and other similar projects. Often times I have come to realize that CV (especially OCR) was not the answer.
I have decided to write about OCR after several attempts of explaining the costs required to make robust OCR happen. Often times for clients I will even recommend against OCR using Jedi mind tricks (a staple in software engineering).

But I digress, let’s check out the exciting world of OCR!
First, What is heck is OCR? #
Optical Character Recognition involves an intersection of pattern recognition, computer vision and artificial intelligence. Usually, OCR is used to convert text from images/video in to computer readable text.
Some examples include:
- Reading license plate numbers and searching for the car in a database
- Storing collected business cards into contacts
- Converting class handwritten notes into a word document, etc.
Demo #
There are several libraries to try OCR with, for example OCRAD.js.
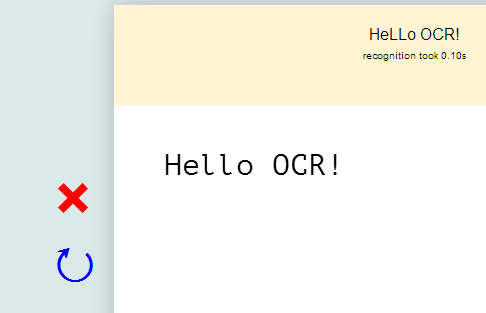
Click on the image to go to the demo page
OCRAD is GNU C library that was compiled to Javascript using Emenscripten. This library is amazing for frontend/client side OCR but if you try several differing fonts (the blue round arrow) you will notice that the text extraction is not as desirable.
Examples:First #
| Font Problems | Digit Errors |
|---|---|
 |
 |
There are several other open source libraries such as Tesseract and more. But the point to notice is that OCR is not a silver bullet. Or rather OCR alone is usually not enough for a real world web application.
Next time on Naive Data Engineering #
In the next version of this series I will discuss what can and shouldn’t be done with OCR. We will then look at how to digest OCR results and post process them to make proper use of the results.